iOSWorld · Leaderboard
Leaderboard.
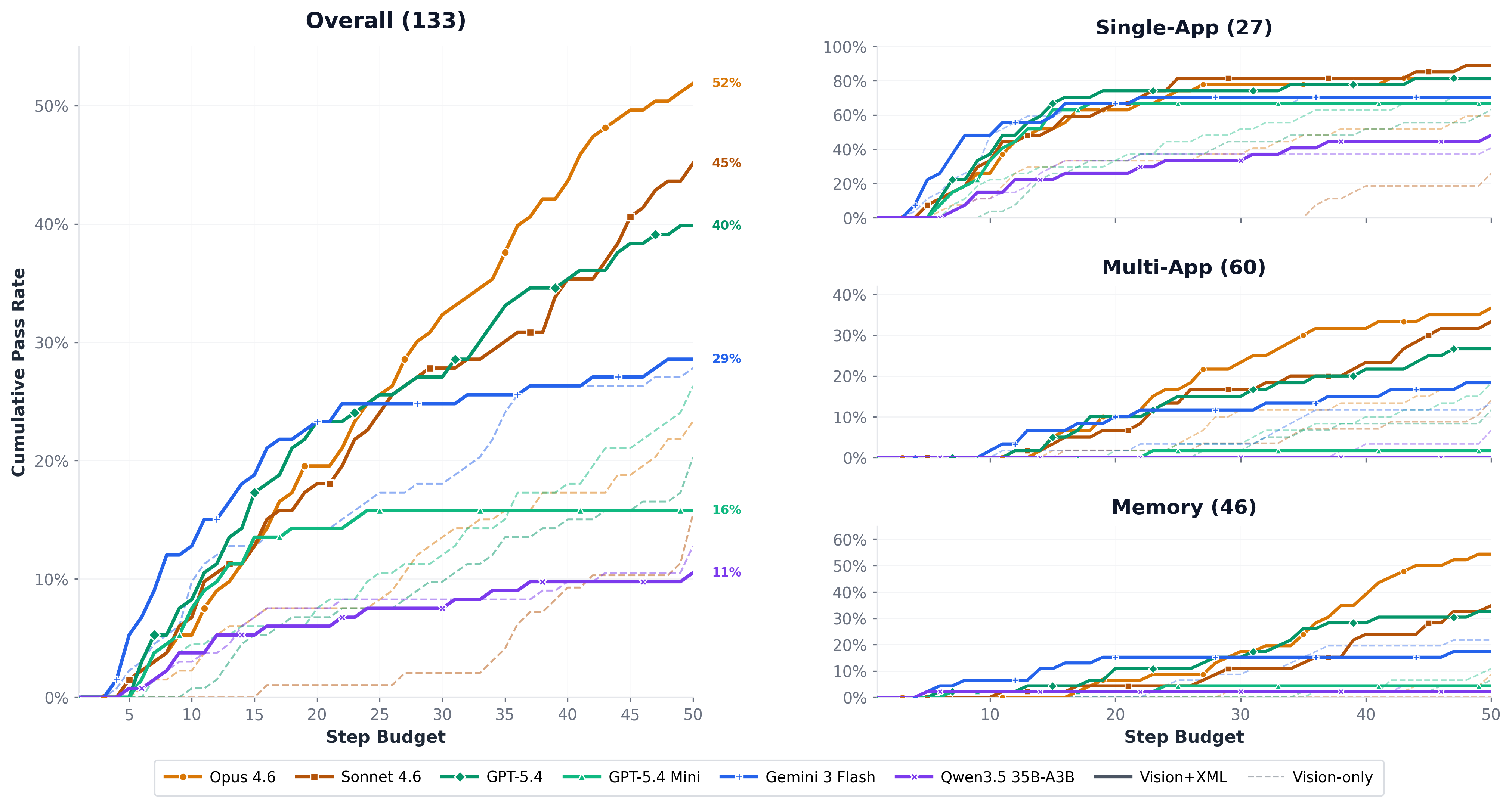
Six models, twelve configurations. Each task receives a binary pass/fail from a GPT-5.4 Mini judge that reviews the agent's full trajectory against the rubric. Values in bold lead each column; step counts are averages.
Human–judge agreement on 128 Opus 4.6 trajectories: κ = 0.77 · 89% accuracy · F1 = 0.86.
| Model | Modality | Single (27) | Multi (60) | Memory (46) | Overall (133) | ||||
|---|---|---|---|---|---|---|---|---|---|
| Pass | Steps | Pass | Steps | Pass | Steps | Pass | Steps | ||
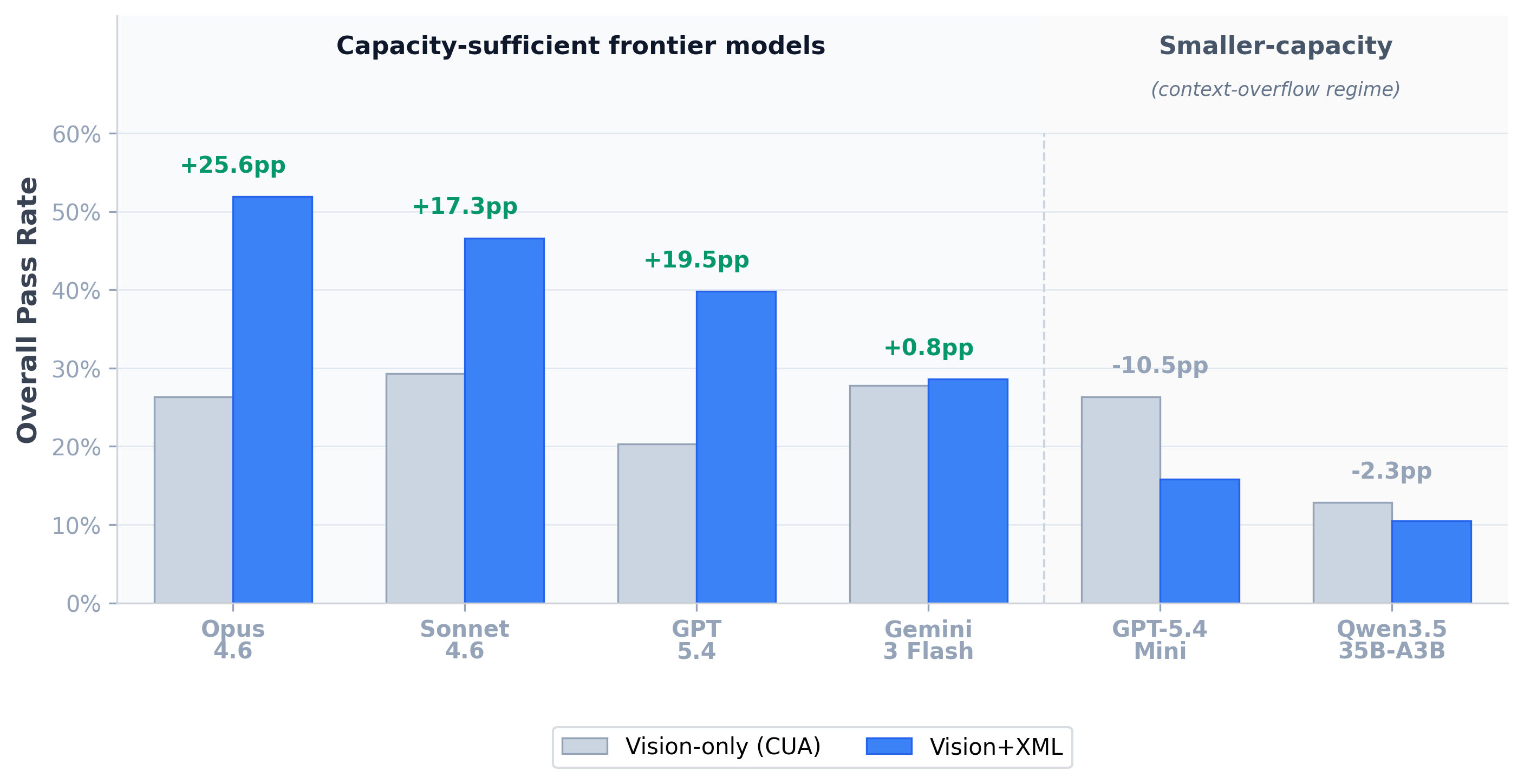
| Opus 4.6 Anthropic | vision-only | 70.4% | 23.1 | 20.0% | 45.5 | 8.7% | 49.4 | 26.3% | 42.3 |
| vision+xml | 81.5% | 16.4 | 36.7% | 38.2 | 54.3% | 39.3 | 51.9% | 34.1 | |
| Sonnet 4.6 Anthropic | vision-only | 77.8% | 26.3 | 21.7% | 46.9 | 10.9% | 49.8 | 29.3% | 43.7 |
| vision+xml | 92.6% | 15.4 | 35.0% | 42.0 | 34.8% | 44.8 | 46.6% | 37.5 | |
| GPT-5.4 OpenAI | vision-only | 63.0% | 32.5 | 11.7% | 48.5 | 6.5% | 48.3 | 20.3% | 45.2 |
| vision+xml | 81.5% | 12.1 | 26.7% | 37.1 | 32.6% | 37.2 | 39.8% | 32.1 | |
| GPT-5.4 Mini OpenAI | vision-only | 70.4% | 24.0 | 18.3% | 46.3 | 10.9% | 48.9 | 26.3% | 42.7 |
| vision+xml | 66.7% | 14.9 | 1.7% | 43.8 | 4.3% | 41.5 | 15.8% | 37.2 | |
| Gemini 3 Flash Google | vision-only | 70.4% | 11.0 | 13.3% | 23.9 | 21.7% | 23.5 | 27.8% | 21.2 |
| vision+xml | 70.4% | 11.5 | 18.3% | 38.0 | 17.4% | 33.3 | 28.6% | 31.0 | |
| Qwen3.5 35B-A3B Alibaba (open) | vision-only | 40.7% | 23.0 | 6.7% | 36.2 | 4.3% | 33.4 | 12.8% | 32.6 |
| vision+xml | 48.1% | 31.4 | 0.0% | 43.9 | 2.2% | 37.9 | 10.5% | 39.3 | |
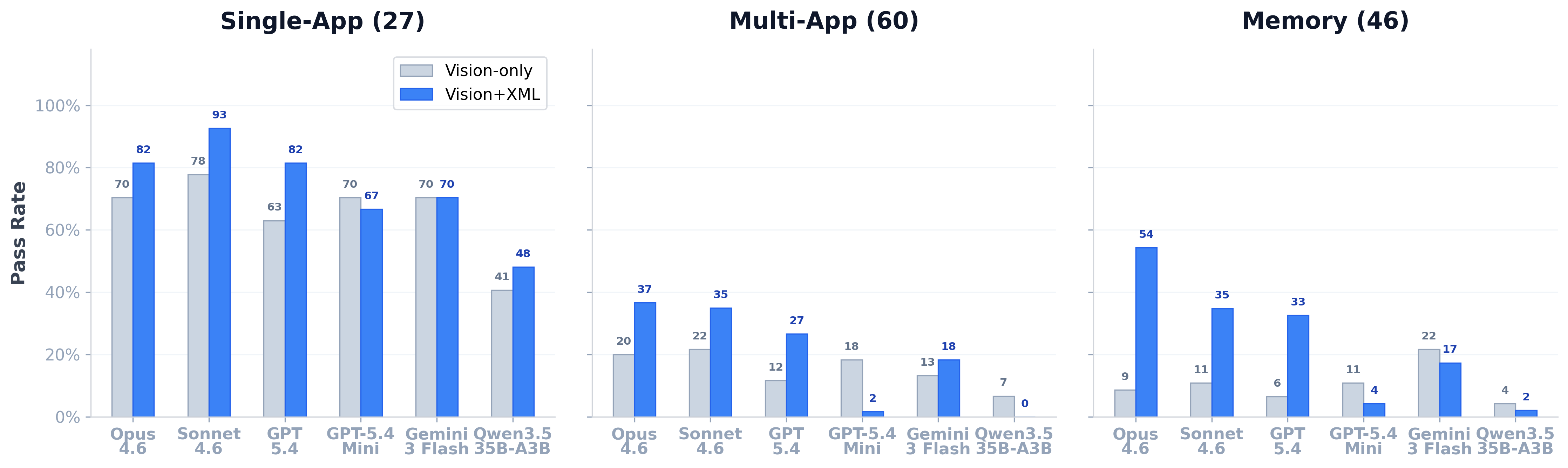
Best · multi-app
36.7%
Opus 4.6 + vision+XML. Multi-app remains the hardest category in the suite.
Best · single-app
92.6%
Sonnet 4.6 + vision+XML. With XML access, single-app tasks are nearly solved.
Best · memory
54.3%
Opus 4.6 + vision+XML. Largest absolute lift from XML (9% → 54%).