Single-app · 27
27
Basic navigation and interaction within one application.
"Set a 6:45 AM alarm in Clock labeled Gym and confirm it's set."
e.g. clock, fitness, food logging
Lawrence Keunho Jang · Mareks Woodside† · Geronimo Carom† · Andrew Jang† · Jing Yu Koh · Ruslan Salakhutdinov
Carnegie Mellon University · †Equal contribution
A useful phone agent will have to be personally intelligent — it must reason over the user's identity, history, and preferences as they exist on their device, not just instructions in an impersonal sandbox. Existing phone-agent benchmarks evaluate the latter and largely ignore the former. We introduce iOSWorld, the first interactive native iOS simulator benchmark built around a persistent user identity that spans 26 newly-built iOS apps with interconnected data. iOSWorld includes 133 tasks across three categories of increasing difficulty. Evaluating leading frontier and open-source computer-use models under both vision-only and privileged vision+XML settings, the best configuration reaches 51.9% overall but only 36.7% on multi-app tasks. Privileged XML access improves the stronger frontier models by up to 26 points; smaller models do not benefit. We release iOSWorld in full — apps, seed data, tasks, rubrics, and evaluation code.

Figure 1. The home screen for our fictional persona, Jordan Avery. All 26 iOSWorld apps appear here.
A person's phone is not a blank slate. Transactions, messages, social connections, and financial records accumulate across many applications, forming a record that any useful assistant would need to understand and navigate. We use the term personally intelligent to describe the corresponding agent capability: reasoning over a user's identity, history, and preferences as they actually exist on the device, rather than executing turn-by-turn instructions in isolation.
Current benchmarks for phone agents ignore this dimension. Tasks are issued against stock app states without persistent user data, no cross-app continuity, and no real notion of a user. An agent that can tap the right button on a settings screen but cannot figure out how to use its owner's most common commute route has not demonstrated useful capability.
Existing interactive mobile-agent benchmarks target Android (AndroidWorld, AndroidLab, SPA-Bench, B-MoCA, GUI Odyssey). iOS serves over 2.5 billion active devices and accounts for roughly 58–60% of U.S. mobile OS usage, but no interactive iOS-simulator benchmark exists, and no mobile benchmark on any platform seeds applications with a persistent user identity. iOSWorld is the first.
One persona, twenty-six SwiftUI apps, interconnected seed data.
All 26 applications share a single user identity: Jordan Avery, a San Francisco–based professional living at 410 Brannan Street who works at Northstar Studio and trains for a half marathon. Jordan's contacts — Maya Patel, Leo Chen, Kai Santos — appear as messaging correspondents, payment recipients, mail senders, professional connections, and team members.
The data is genuinely interconnected: a Chipotle order in QuickBite produces a charge in MyBank and a receipt in Mail; an upcoming SFO→JFK flight in SkyTrip aligns with a hotel booking in StayFinder and a calendar reminder in Notes. These cross-references make multi-app and memory tasks require evidence from more than one application.
Apps were developed in SwiftUI and manually verified for correct navigation, data rendering, and seed-data consistency. They span finance, messaging, travel, food, shopping, productivity, entertainment, fitness, sports, utilities, and professional networking. Two build on open-source foundations (Notes from snowNotes, Cinephile from MovieSwiftUI). User data is encoded in Swift seed fixtures and JSON snapshots loaded at build time.

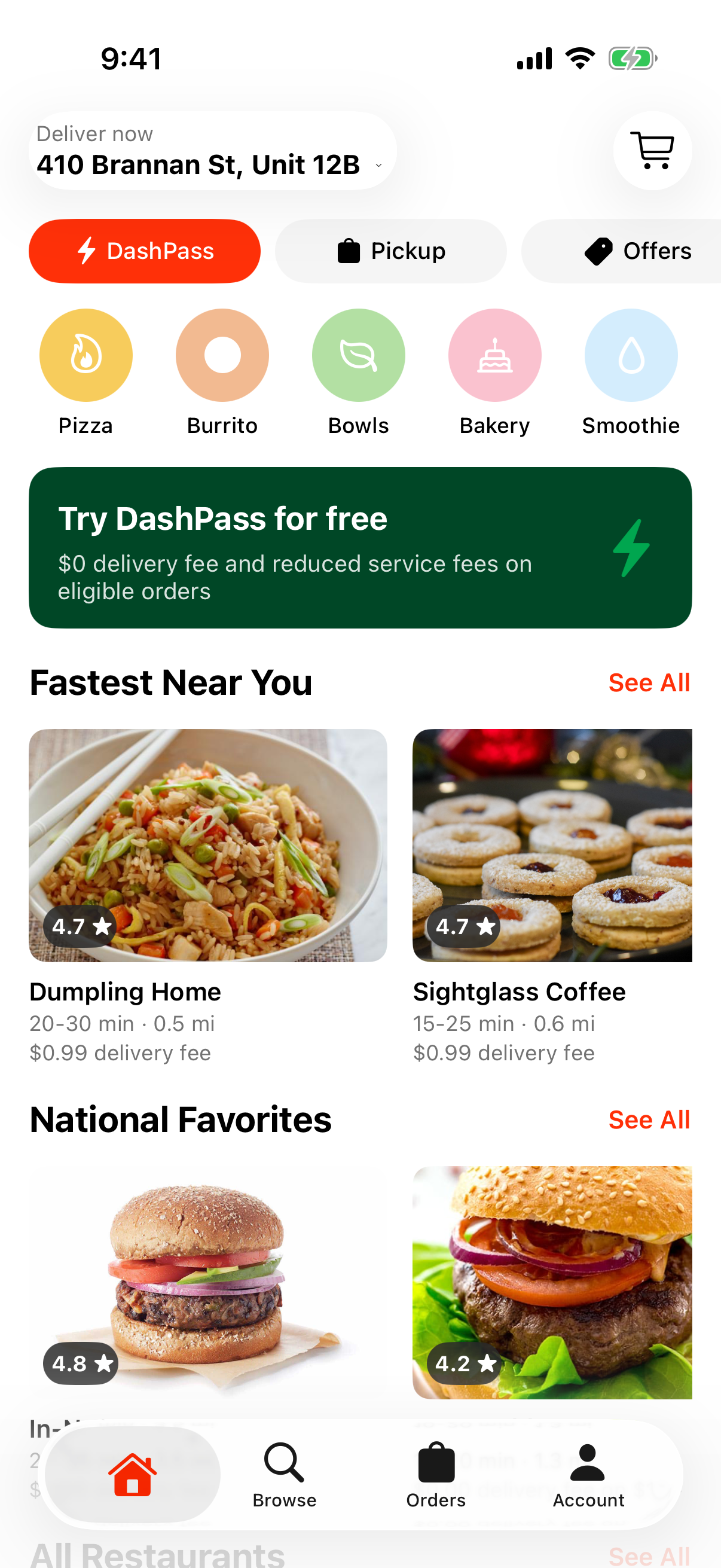
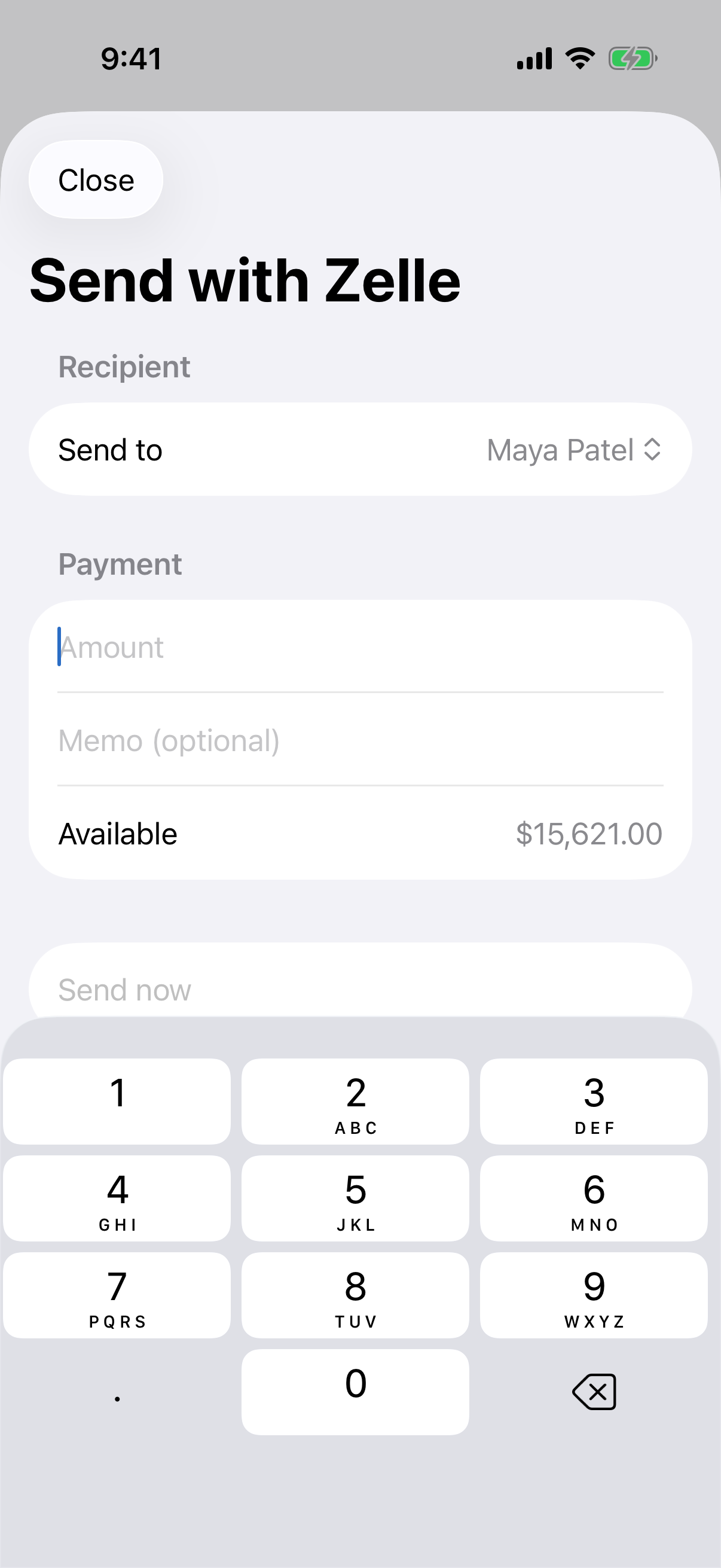
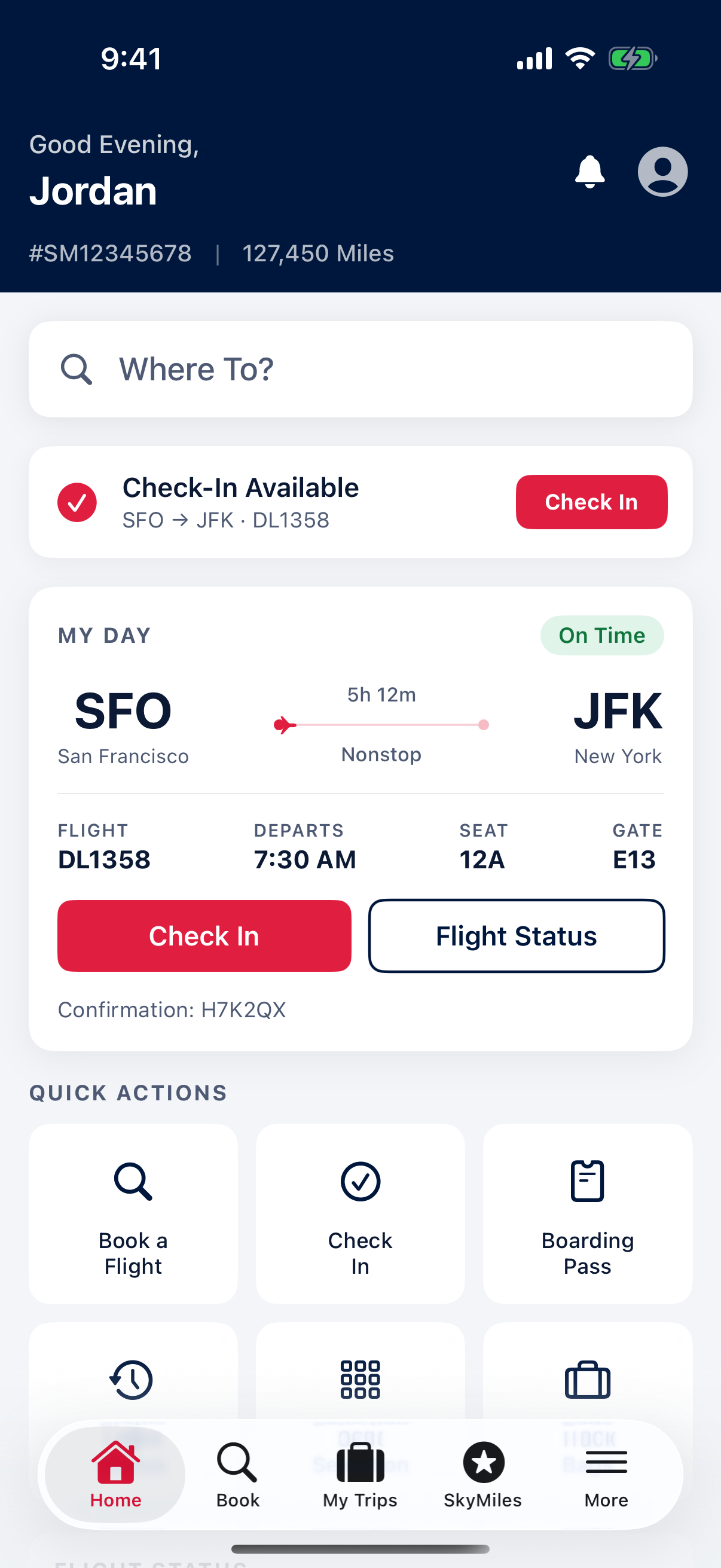
133 tasks across three categories of increasing difficulty.
Each task is accompanied by a rubric — independently verifiable criteria that decompose the objective into steps. The benchmark contains 1,123 rubric items across 133 tasks (mean 8.4 per task, range 4–13). Tasks were generated by Claude Code with full access to each app's source code and seed data, then reviewed and corrected by human annotators. Forty-four of the 175 candidate tasks required corrections; we trimmed the set to 133.
Basic navigation and interaction within one application.
"Set a 6:45 AM alarm in Clock labeled Gym and confirm it's set."
2–8 applications. Information must move between them.
"Check my recent Chipotle order in QuickBite. Then check MyBank for the corresponding charge. Find the receipt email in Mail and note any price differences in Notes."
Patterns the user never explicitly states.
"Look at my CityRide app and figure out my most common route based on saved locations. Then request a ride along that route."
Six models, two observation modalities, an LLM-as-a-judge.
We evaluate five frontier computer-use models — Claude Opus 4.6, Claude Sonnet 4.6, GPT-5.4, GPT-5.4 Mini, Gemini 3 Flash — and one open-source baseline, Qwen3.5 35B-A3B (an open-weights MoE served via vLLM with the official Qwen3-VL mobile-agent cookbook). Each model is tested under both observation modalities, yielding twelve configurations. All runs use a maximum of 50 interaction steps per task with screenshots at 1536-pixel maximum dimension.
Vision-only. The agent receives a screenshot at each step. It must visually identify UI elements, estimate their coordinates, and infer the application state from pixels alone. Six actions: tap_xy, type, swipe, home, wait, stop. Coordinates normalized to a 0–1000 grid.
Vision + XML. Adds a cleaned XCUITest accessibility tree (≤ 200 elements, ≤ 15 levels deep) and four extra actions: tap (by accessibility identifier), launch_app, terminate_app, open_url. This is a privileged-access condition; vision-only reflects deployable capability.
Each task is scored after the trajectory by a GPT-5.4 Mini judge that reviews the agent's full screenshot+action history against the per-task rubric. Human validation on 128 Opus 4.6 trajectories confirms substantial agreement: κ = 0.77 at task level (89% accuracy, F1 = 0.86).
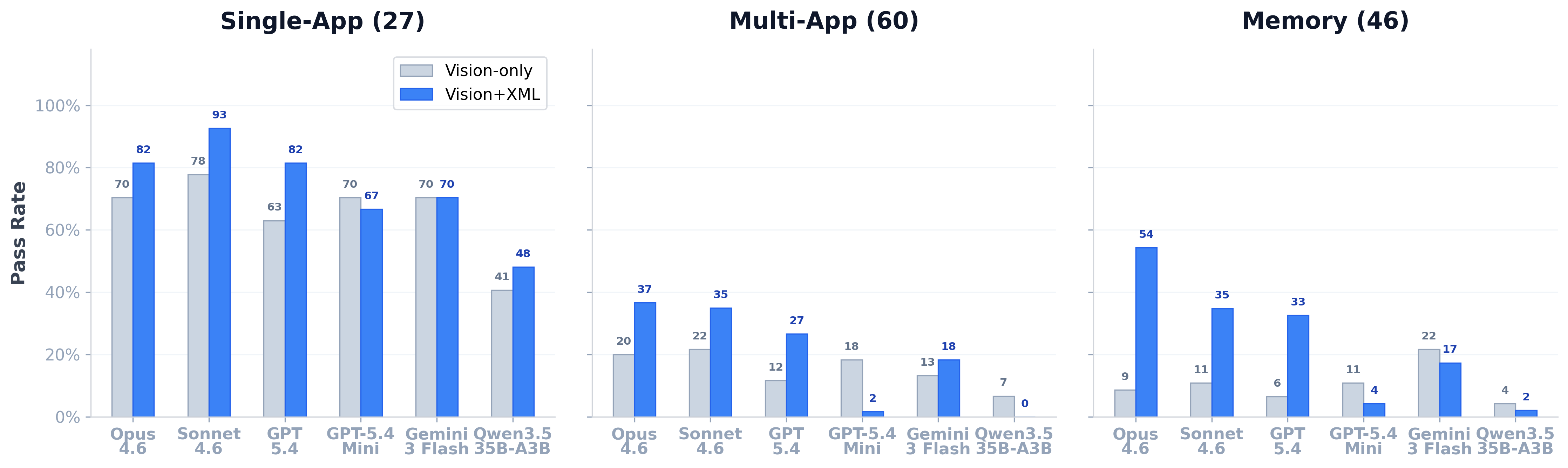
Frontier models reach 93% on single-app, 37% on multi-app.
With vision+XML, Sonnet 4.6 reaches 92.6% on single-app tasks, and Opus 4.6 leads on memory at 54.3% and on multi-app at 36.7%. Multi-app remains the hardest category. In vision-only mode, frontier models cluster between 20% and 29% overall.
| Configuration | Single (27) | Multi (60) | Memory (46) | Overall (133) |
|---|---|---|---|---|
| #1 Opus 4.6 vision+xml | 81.5% | 36.7% | 54.3% | 51.9% |
| #2 Sonnet 4.6 vision+xml | 92.6% | 35.0% | 34.8% | 46.6% |
| #3 GPT-5.4 vision+xml | 81.5% | 26.7% | 32.6% | 39.8% |
Why XML helps frontier models, why it hurts smaller ones, and what failure looks like.
The vision-to-XML gap is large due to iOS-specific factors: dense interfaces with small touch targets, app launching that requires home-screen navigation (which launch_app bypasses), the accessibility tree exposing off-screen elements, and the absence of a hardware back button. Across the 26 Opus tasks where vision-only fails (score < 0.5) and vision+XML passes outright, ∼70% feature a home-screen / app-switching failure eliminated by launch_app.
The lift is not uniform. Memory sees the largest absolute improvement (Opus: 9% → 54%) because the tree exposes element labels and values directly. Multi-app benefits too (Opus: 20% → 37%) once the agent can launch apps and target elements precisely.
Two smaller-capacity configurations break the gain pattern. GPT-5.4 Mini lands at 16% with vision+XML versus 26% vision-only — the additional ∼3,100 tokens per step appear to push it past its effective context limit. Twenty-two of the 35 tasks Mini solves vision-only become failures under XML.
Qwen3.5 35B-A3B shows a related but more severe pattern: XML drops it from 13% to 11% overall and from 7% to 0% on multi-app, with ∼42% of its 119 XML failures dominated by action loops. The accessibility tree helps when the model can use it and becomes noise when it cannot.
We classify all 422 vision+XML failures across the five frontier models into four mutually exclusive modes:
Timing out dominates multi-app (54%) and memory (47%); premature stops dominate single-app (50%). GPT-5.4 Mini gives up on 46% of its failures; Gemini loops on 15%; Qwen3.5 has a different profile entirely (∼42% looping across 119 XML failures).
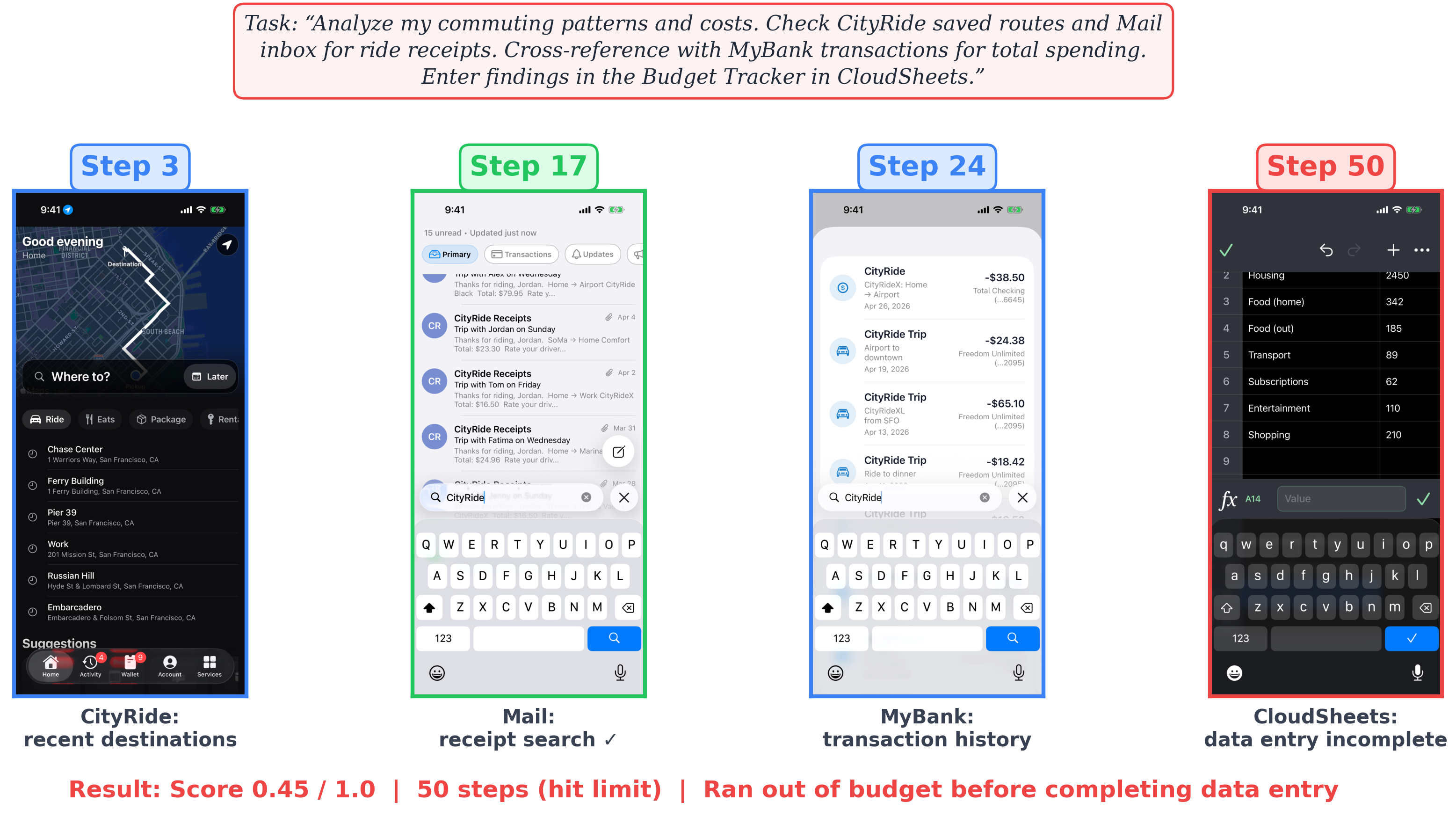
Curated runs from the top-scoring configuration.
A selection of 20 representative runs below. Each trajectory renders the task, the rubric, the per-step iOS screenshot, and the agent's action. All come from Opus 4.6 + vision+XML — the highest-scoring configuration in the paper.
Log today's breakfast in CalTrack — search the food database for 'oatmeal', add a serving, and give me the calories and macros.
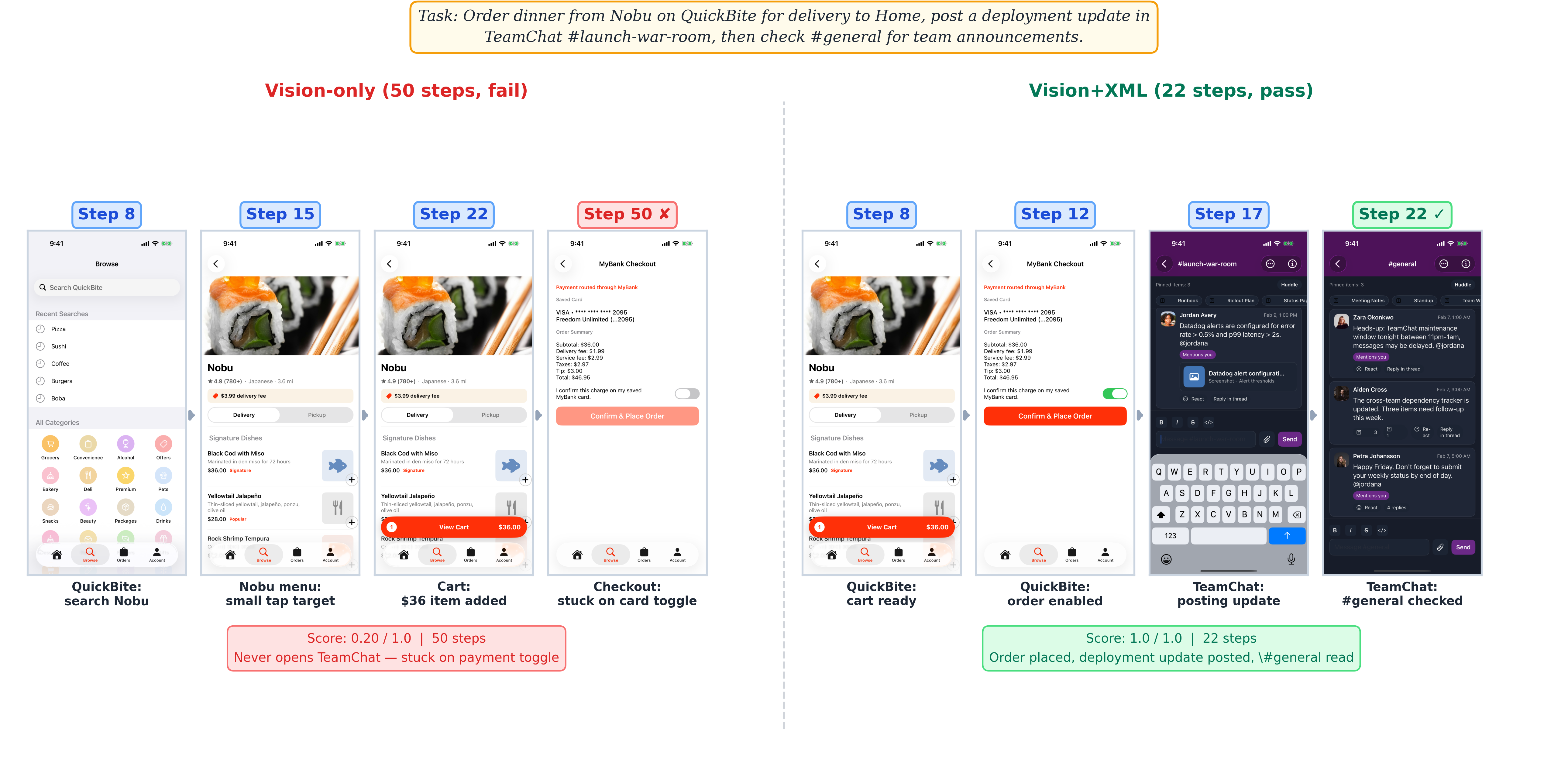
Open QuickBite and check my most recent Chipotle order details and total. Then check my MyBank credit card transactions for the corresponding charge and note the QuickBite total and the bank charge; report whether they roughly match. Also check my Mail inbox for a QuickBite receipt email, and add a note about the Chipotle expense to my Notes Shopping List. What are the order items, order total, bank charge amount, and email receipt amount?
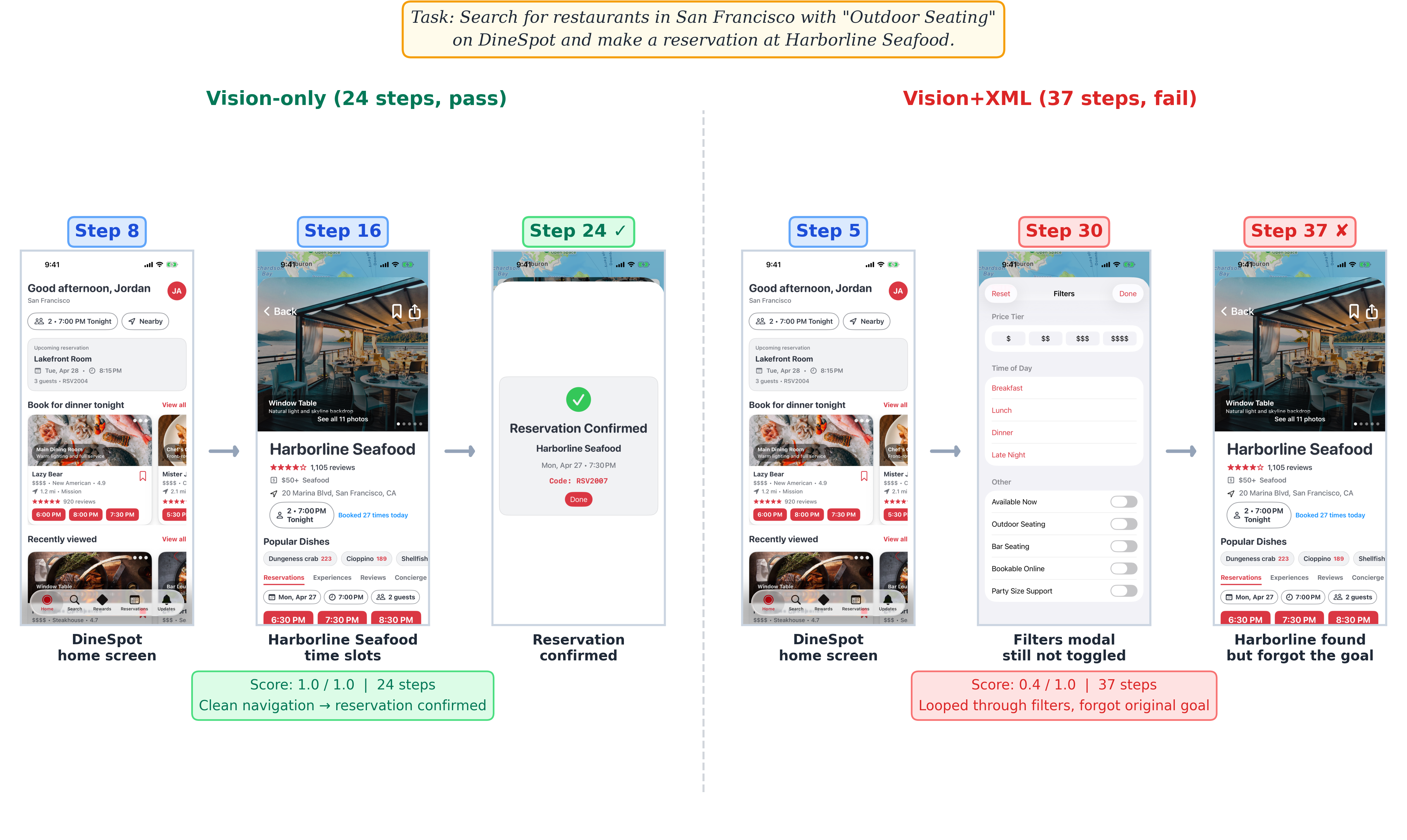
Look at my CityRide app and figure out my most common route based on my saved locations. Then request a ride along that route and tell me the route and estimated fare.
Frontier models solve up to 93% of single-app tasks with privileged vision+XML access, but the best overall configuration still reaches only 37% on multi-app and 54% on memory tasks; the open-source Qwen3.5 35B-A3B baseline remains far behind (11% overall, 0% multi-app, ∼42% loop-failures). Forty-eight percent of frontier failures are timeouts.
Closing the gap to personally intelligent phone agents will require progress on loop recovery, retrieval-augmented memory, and user-aware planning. We release iOSWorld in full — apps, seed data, tasks, rubrics, and evaluation code — to support reproducible research.
All apps, seed data, tasks, rubrics, and evaluation code are open source under Apache 2.0.
@misc{jang2026iosworld,
title = {iOSWorld: A Benchmark for Personally Intelligent Phone Agents},
author = {Jang, Lawrence Keunho and Woodside, Mareks and Carom, Geronimo
and Jang, Andrew and Koh, Jing Yu and Salakhutdinov, Ruslan},
year = {2026},
eprint = {arXiv:XXXX.XXXXX},
archivePrefix = {arXiv},
primaryClass = {cs.AI}
}